本文将罗列整理计算机组成原理中存储器相关的知识。
编址和端模式 链接到标题
字节存储单元 链接到标题
即一个存储单元内存放一个字节(8bit)的数据,相应的地址称为字节地址。
一般题目中用以 B 结尾的单位(例如:8MB)或 8 根数据线表示存储容量的形式来暗示编址是字节。
字存储单元 链接到标题
即一个存储单元内存放一个字(不定长)的数据,相应的地址称为字地址。
一般题目中以类似 32M * 32 或 32 根数据线表示存储容量的形式来暗示编址是字(例子中为 1word = 32bit)。
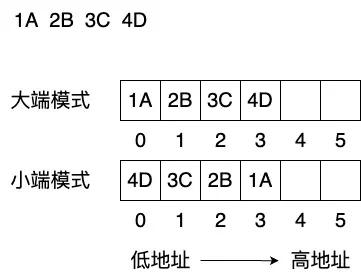
端模式 链接到标题
大端模式:将一个字的高的有效字节放在内存中的低地址端,低的有效字节放在内存中的高地址端。
小端模式:将一个字的低的有效字节放在内存中的低地址端,高的有效字节放在内存中的高地址端。
示意图如下:
存储器的分类 链接到标题
ROM 链接到标题
ROM 用于存储不变或基本不变的数据与程序。
RAM 链接到标题
RAM 用于存储数据与程序,断电会丢失数据。
SRAM 链接到标题
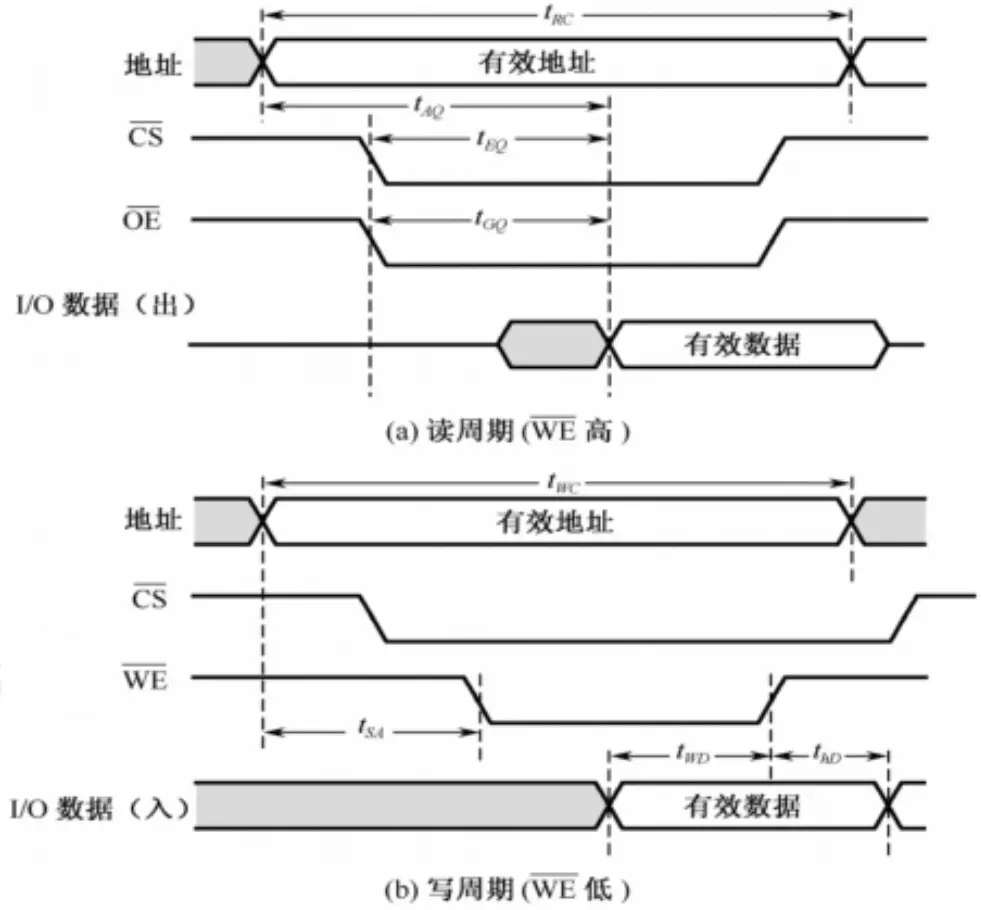
SRAM 用于高速缓存(即 Cache),控制它的信号要求有稳态(信号可以保持一段时间不变),地址信号先到,控制信号其次,数据信号最后。
读写周期时序图如下:
DRAM 链接到标题
DRAM 用于内存。
因使用电容存储数据,电容会随着时间的流逝一点点丢失电荷,因此需要刷新操作来保证数据不会丢失,有如下三种刷新方式:
- 集中刷新方式:把每一个刷新周期分为读写和刷新两个部分,这样的设计存在死区(即某一段时间内内存无法进行读写操作)。
- 分散刷新方式:把刷新操作均匀的分散到刷新周期中,这样的设计会使存取周期大于存取时间。
- 异步刷新方式:在刷新周期中空闲时间内刷新,这样的设计需要用到其他硬件。
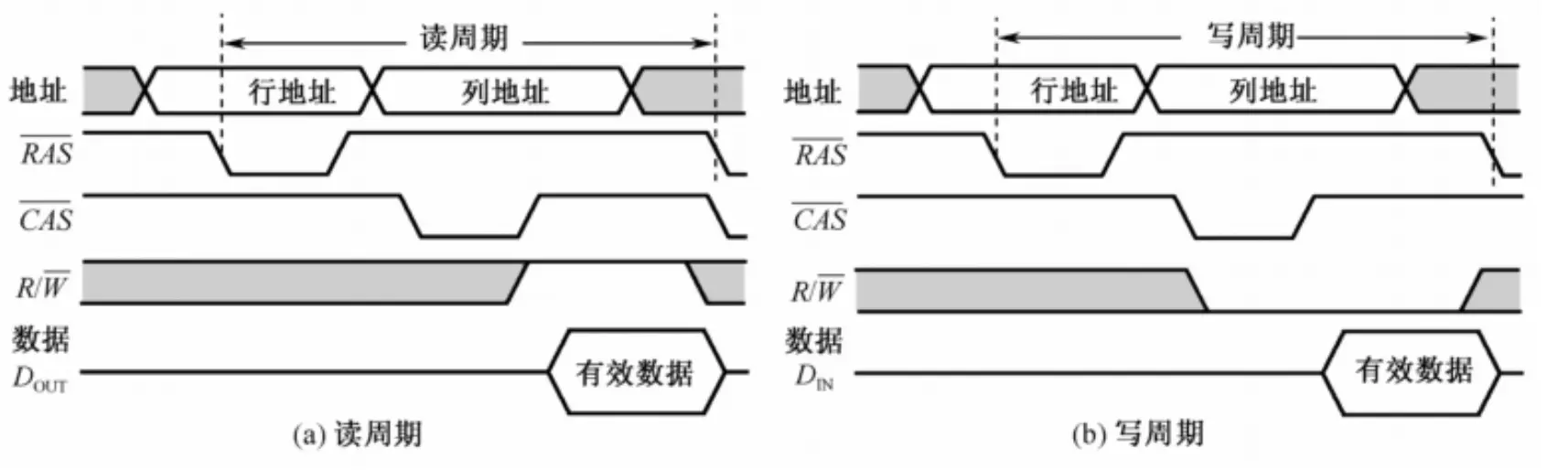
DRAM 的读写控制要求与 SRAM 一致,区别是地址被分为了行地址与列地址两部分,因此也需要行选通信号与列选通信号来区分行列地址,周期时序图如下:
存储器的扩展 链接到标题
很多时候我们手头的存储芯片所提供的参数与我们的需求不符合,因此我们需要对已有芯片做一些扩展处理以达到我们的要求,一般有如下三种扩展方式:
位扩展 链接到标题
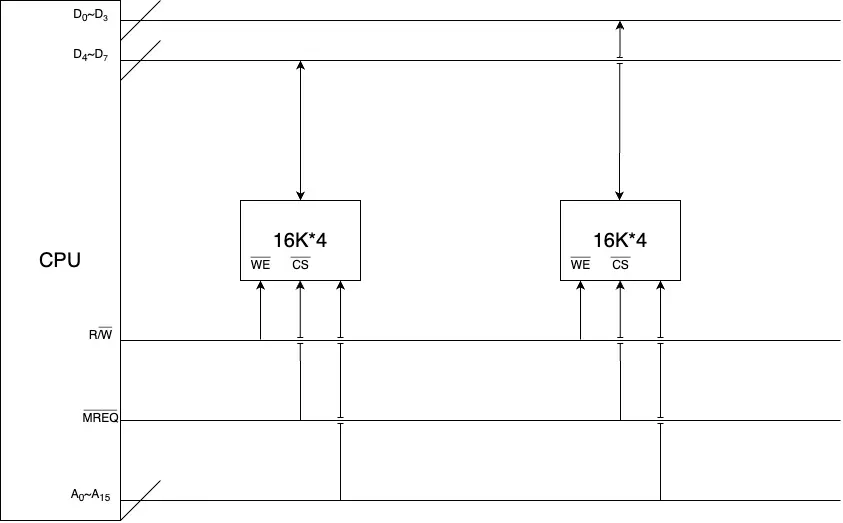
当手头芯片每个存储单元所能存储的位数小于我们所需的时,我们需要对其进行位扩展,如将 16k * 4 的芯片扩展为 16k * 8 的内存。
位扩展时地址线与控制线公用,数据线分开连接,cpu 在读写某个存储单元时会同时对多个存储芯片上具有相同地址的多个存储单元进行操作。
接线图样例如下:
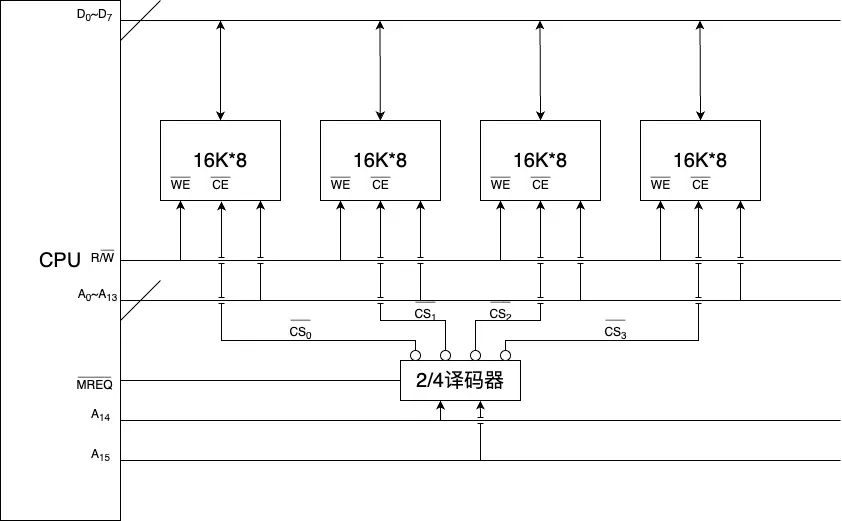
字扩展 链接到标题
当手头芯片的存储单元数量小于我们所需的时,我们需要对其进行字扩展,如将 16k * 8 的芯片扩展为 64k * 8 的内存。
位扩展时地址线的低位段、控制线中的 $R/\overline{W}$ 与数据线公用,由地址线的高位段提供译码器来决定片选信号。
16k * 8 的芯片扩展为 64k * 8 的内存需要用到四片内存,$2^2=4$,因此地址线的高两位将决定哪一片芯片被选中,具体对应译码规则如下:
$\overline{A_{14}A_{15}} = \overline{CS_0}$
$\overline{A_{14}}A_{15} = \overline{CS_1}$
$A_{14}\overline{A_{15}} = \overline{CS_2}$
$A_{14}A_{15} = \overline{CS_3}$
接线图样例如下:
同时位扩展与字扩展 链接到标题
当手头芯片的存储单元数量与单个存储单元可以存储的位数均小于我们所需的时,我们需要对其同时进行位扩展和字扩展,单独流程与上文一致,但有一些规则如下:
- 先进行位扩展再进行自扩展;
- 只读芯片在地址低端,可读芯片在地址高端;
- 大容量芯片在地址低端,小容量芯片在地址高端;
- 只读区不接控制线中的 $R/\overline{W}$ 线。
存储器加速 链接到标题
内存的读写速度比起 cpu 的运行速度来说算是十分慢的了,因此我们需要在硬件层面应用一些技术以提高内存的读写速度。
高级 DRAM 链接到标题
高级 DRAM 是用于提高在突发(猝发)访问情况下内存读写速度的一项技术。
突发访问指的是在存储器同一行中对相邻的存储单元进行连续访问的方式。
由于访问的地址是连续的,因此只需要向存储器发送一次行地址,然后按照一定的顺序依次发出列选择信号即可访问相应的目标存储单元。
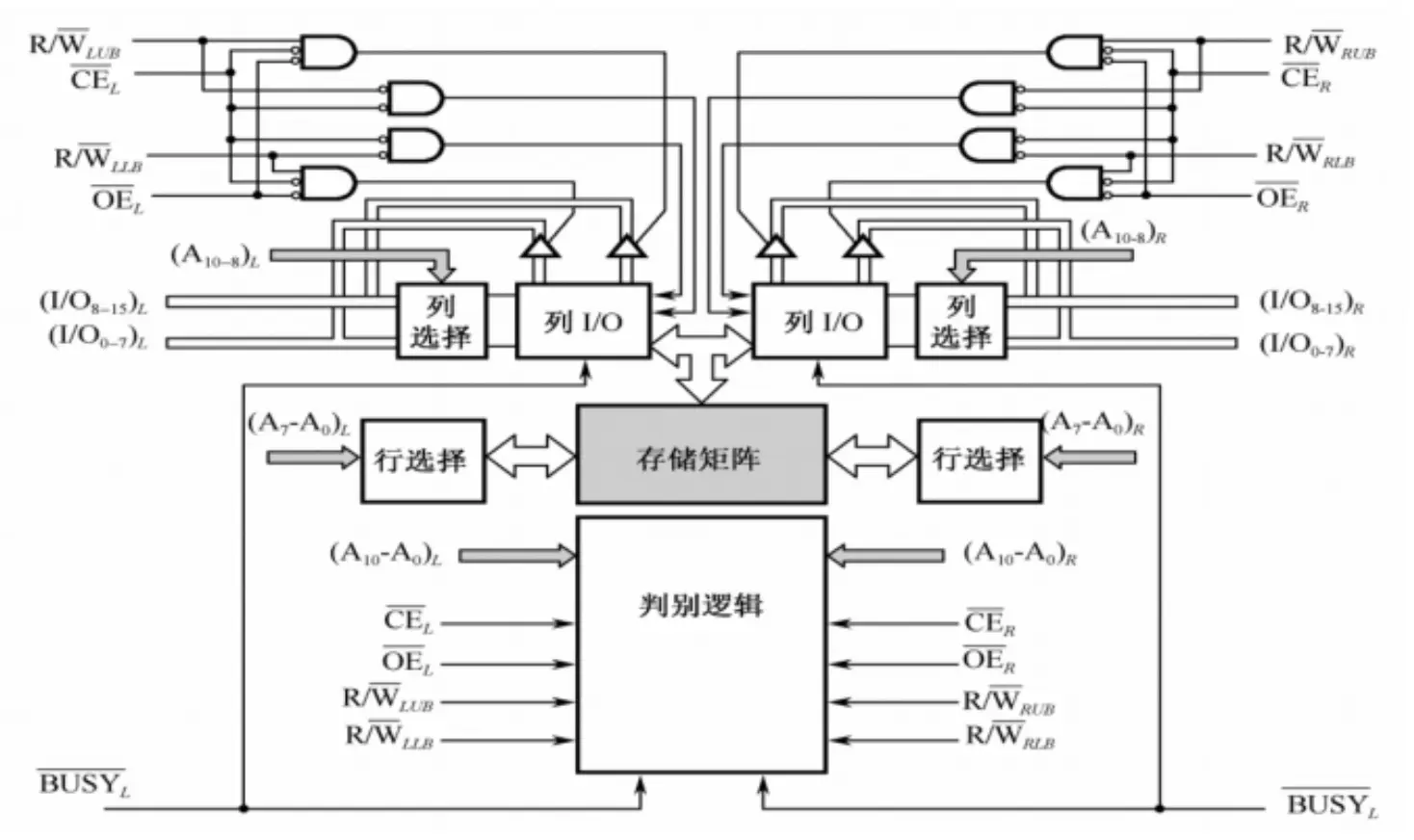
双端口存储器 链接到标题
双端口存储器可以简单理解为给一片内存芯片配备两套甚至多套读写硬件,使其可以在同一时刻或极小的时间间隔内读写多次,示意图如下:
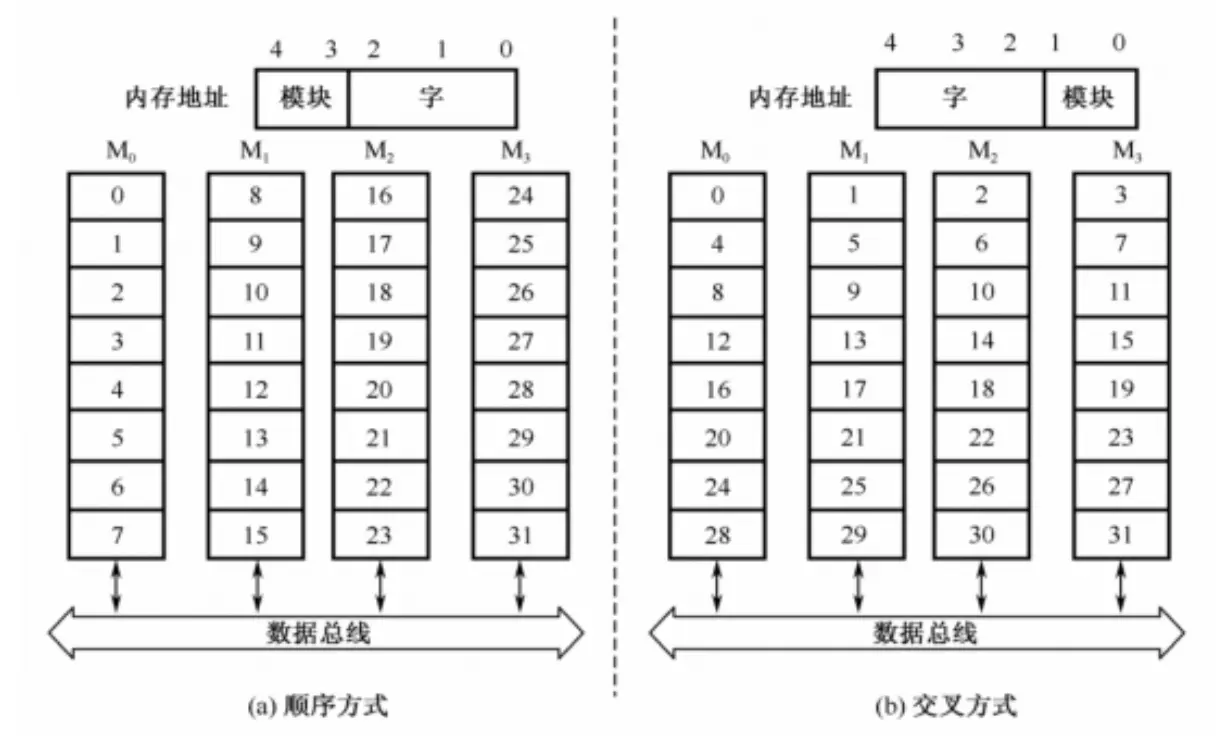
多模块交叉存储器 链接到标题
多模块交叉存储器是一种由若干个模块组成的,而内存地址仍是线性编址的,因此这些地址在各模块中存在以下两种安排方式:
- 顺序方式:即像普通存储器一样,一个模块内存储连续的几个字;
- 交叉方式:即相邻的几个字被分配到了相邻的几个模块内。
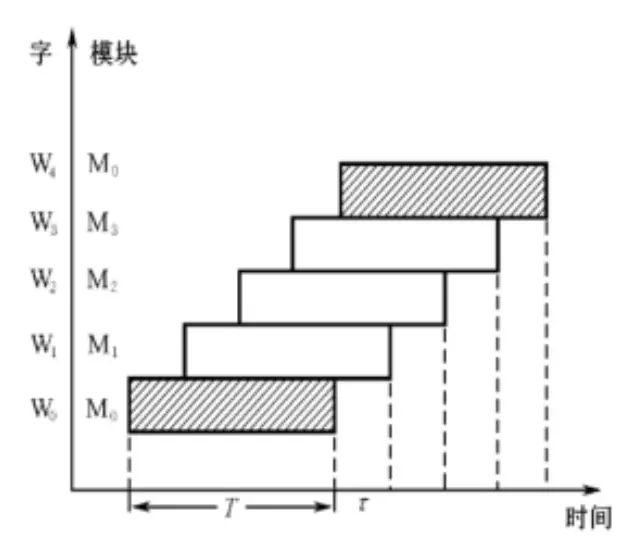
读取 n 个字的时长如下:
顺序方式:$nT$
交叉方式:$T+(n-1)\tau$
其中 T 为模块存取一个字的存储周期,$\tau$ 为总线传输周期,n 为模块总数,且 $n \ge T/ \tau$ 。
流水线(交叉方式)方式存取示意图如下:
cache 存储器 链接到标题
SRAM 的读写速度远快于 DRAM,因此由 SRAM 构成 cache 拥有比内存更快的读写速度,可以用于解决 CPU 与主存之间速度匹配的问题。
几个基本概念 链接到标题
- cache 以 字 为单位与 CPU 进行数据交换
- cache 以 块 为单位与主存进行数据交换
- cache 以 行 为单位进行数据存储
- 一个字包含一个或多个字节
- 一个块包含多个字,是定长的(题目会提供大小)
- 一个行与一个块一样大
需要注意的是,cache 的行大小通常只包括数据部分的大小,用于储存主存区号的标记部分不计入在内。
当 CPU 读取一个字时,首先通过 cache 中的控制硬件根据该字的地址判断该字是否在 cache 中,如果是则 cache命中,立即将该字的数据传给 CPU,否则为 cache缺失,从主存中将该字传给 CPU,并且将包含有这个字的整个数据块传到 cache 中。
有关公式 链接到标题
- cache 完成的存取次数 $N_c$
- 内存完成的存取次数 $N_m$
- cache 命中率 $h=\frac{N_c}{N_c+N_m}$
- 命中时 cache 的访问时间 $t_c$
- 未命中时主存的访问时间 $t_m$
- 平均访问时间 $t_a=ht_c+(1-h)t_m$
- 访问效率 $e=\frac{t_c}{t_m}=\frac{1}{r+(1-r)h}$ ($r=\frac{t_m}{t_c}$)
地址变换 链接到标题
因为 cache 对于 CPU 来说是透明的,即 CPU 不知道 cache 的存在,只知道通过一个地址来读写数据,因此需要一套机制来通过内存地址判断 cache 是否命中,并以此为据选择从 cache 或主存中读写数据。
cache 数据块大小称为行,主存的数据块大小称为块。
行与块等长,每个块都若干个连续的字组成。
有如下三种变换方式:
全相连映射方式 链接到标题
简单来说就是 cache 中的每一行都能映射中的任何一块。
主存中块的地址会被存在标记(tag)部分,块的数据会被存在行内。
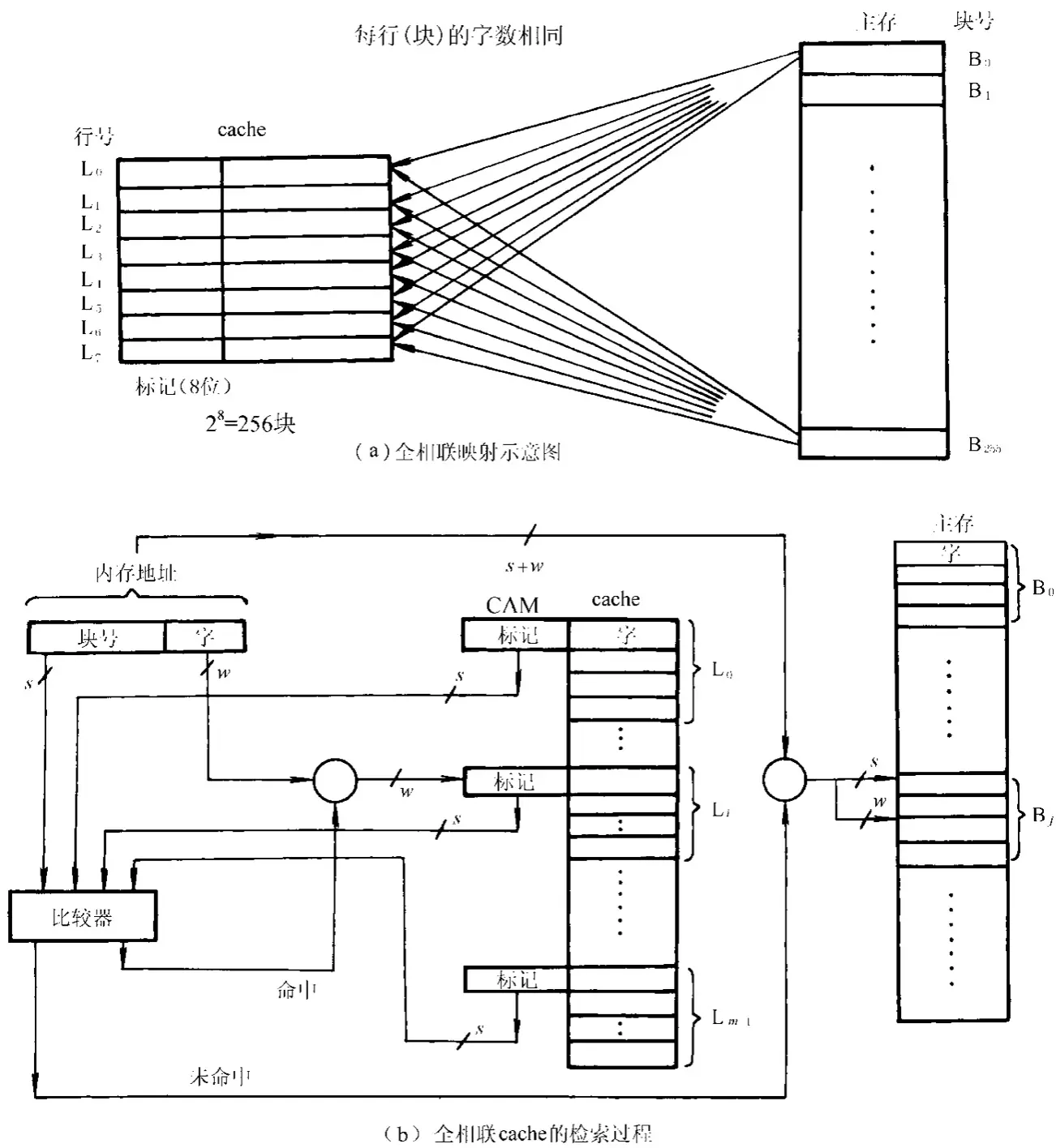
从图中可以看到主存地址在 cache 的比较过程中被分为了块号和字地址两部分。
其中块号将会与 cache 的标记部分进行比较,判断两者在主存中是否对应同一个块。如果一致说明 cache 命中,利用字地址就可以从本行中得到目标数据。
这种方式十分灵活,可以在较坏的情况下(即相邻两次访存的地址间隔比较大的情况)获得较高的命中率。
但判断命中较慢,更新也较为复杂。
直接映射方式 链接到标题
这是一种多对一的映射方式。主存会以 cache 的存储空间为单位划分出若干个区,每个区内块的数量与 cache 中行的数量一致,保证 cache 中第 x 行只能映射到主存中某一个区的第 x 行的映射方式即为直接映射方式。
因此 cache 中的行号 i 与主存中的块号 j 有如下关系:
$i=j\mod m$ (m 为 cache 的总行数)
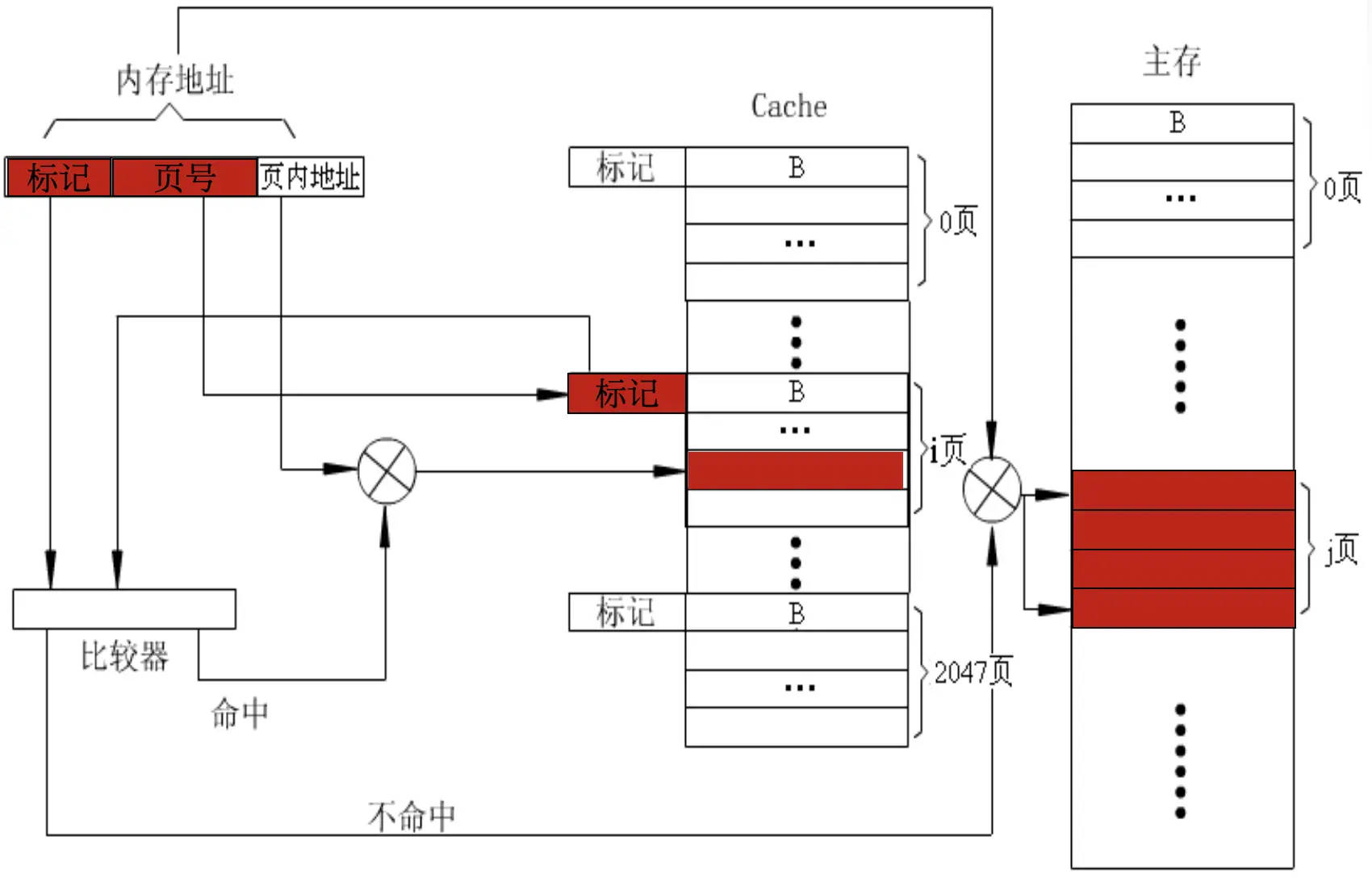
从图中可以看到主存地址在 cache 的比较过程中被分为了区号、区内块号和字地址三部分。
先会用区内块号锁定 cache 中对应的那一行,然后区号将会与该行的标记进行比较,判断两者是否在主存中对应同一个区。如果一致说明 cache 命中,利用字地址就可以从本行中得到目标数据。
这种方式判断命中快,更新简单。
但较坏情况下命中率较低。
组相连映射方式 链接到标题
这是一种结合了以上两种方式的混合映射方式,首先我们将 cache 分成若干组,每组内有 x 行,组间通过直接相连映射的方式映射,组内通过全相连映射方式映射。
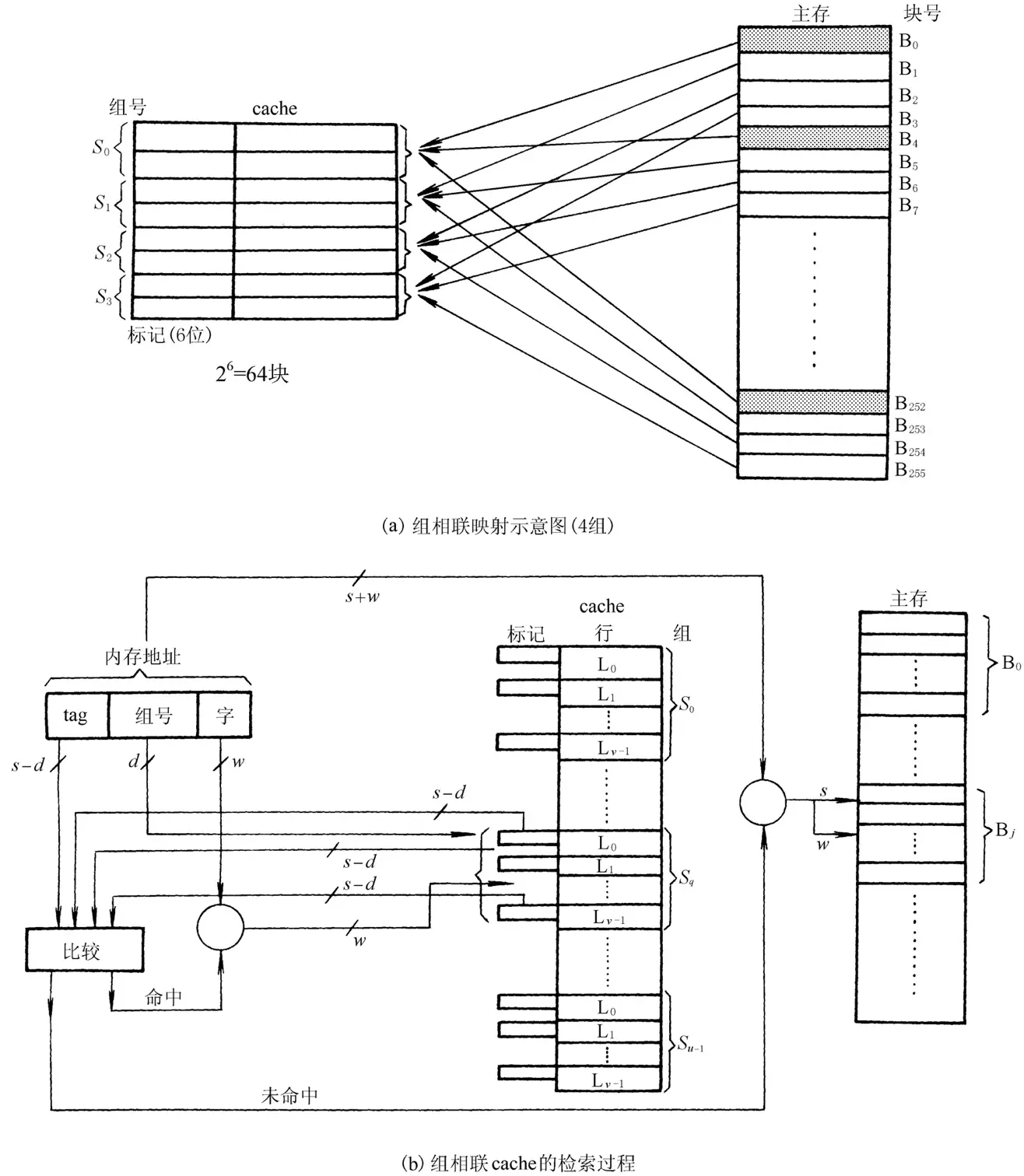
从图中可以看到主存地址在 cache 的比较过程中被分为了区号、区内块号和字地址三部分。
先会用区内块号锁定 cache 中对应的那一组,然后区号将会与该组中每一行的标记进行一一比较,判断两者是否在主存中对应同一个区。如果有任何一个标志与区号相匹配说明 cache 命中,利用字地址就可以从该行中得到目标数据。
很显然这一种方法可以结合上述两种方法的优点,尽量避免它们的缺点。
举例 链接到标题
某主存包含 4k 个块,每块 128 字,cache 由 64 行组成。 要求分别写出全相连、直接映射、2 路、4 路组相连中,cache 的行内地址格式。
4k 个块,即为 $2^{12}$ 个块,每块 $2^7$ 字。cache 有 $2^6$ 行。
全相连:
| 标记 | 字地址 |
|---|---|
| 12 | 7 |
直接映射:
| 标记 | 行 | 字地址 |
|---|---|---|
| 6 | 6 | 7 |
2 路组相连:
| 标记 | 组号 | 字地址 |
|---|---|---|
| 7 | 5 | 7 |
4 路组相连:
| 标记 | 组号 | 字地址 |
|---|---|---|
| 8 | 4 | 7 |
替换策略 链接到标题
由于地址变换中的组相连与全相连映射方式存在多对多的情况,所以在替换时需要用一定的替换策略来约束。
LFU 最不常用算法 链接到标题
使用这种算法的 cache 会给每一行都配一个计数器,每次发生替换后都将被替换的那一行的计数器清零,之后每访问一次该行都会使计数器加一。
在所有可以替换的行内都有数据的情况下进行替换时,会选择计数器上数据最小的那一行(即最不经常访问的那一行)进行替换。
FRU 近期最少使用算法 链接到标题
使用这种算法的 cache 也会给每一行都配一个计数器,每次访问某一行时都会清空该行的计数器,然后给其他所有行的计数器加一。
在所有可以替换的行内都有数据的情况下进行替换时,会选择计数器上数据最大的那一行(即近期最少访问的那一行)进行替换。
随机替换 链接到标题
顾名思义,就是随机选择一行进行替换。
这种算法在硬件上比较容易实现,也不需要用额外的时间来处理计数器的运算与比较,但会使 cache 的命中率下降。
写操作策略 链接到标题
cache 只是主存上一部分数据的副本,对 cache 进行修改后我们需要有一种策略来使主存与其保持一致。
写回法 链接到标题
每次命中时只修改 cache 中的内容,而不直接写入主存。当该行被换出的时候才写入主存。
全写法 链接到标题
每次命中时同时修改 cache 与主存中的内容,这种策略时间开销大。
写一次法 链接到标题
第一次命中时同时修改 cache 与主存中的内容,之后命中时只修改 cache 中的内容,而不直接写入主存,直到该行被换出的时候写入主存。